
Recently me and my father digitized two large books. My father did the bulk of the work by photographing more than 1200 pages. He first photographed all the odd pages and then all the even pages. As with any repetitive task, errors occurred and he missed a few pages.
All the even pages were in one folder and all the odd pages in another. The goal was of course to merge them into a single PDF document. If it wasn’t for the occasional missing pages this could have been straight forward. Just use Apple’s Automator to rename all the files. Automator allows you to give a bunch of files a base name followed by a serial number.
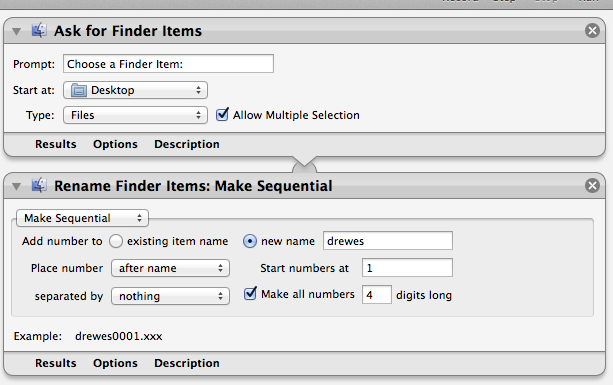
The trick is to serialize the odd pages 1-1200 (e.g. drewes0102) and then the even pages in exactly the same way. This is possible since the even and odd pages are still in separate folders. Next you can use Automator again to add a suffix to the file names.
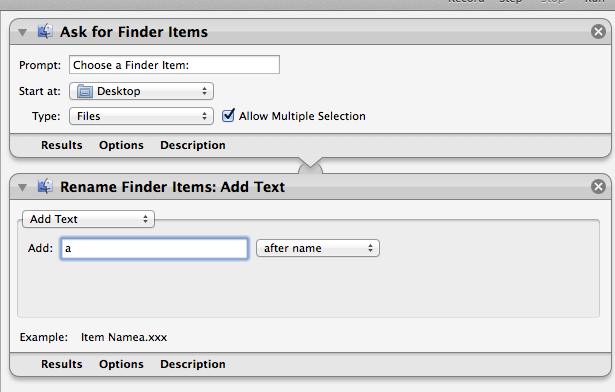
Give the “a” suffix to the odd pages and the “b” suffix to the even pages. You can then move all the files into one directory. They will be sorted as:
drewes0001a
drewes0001b
drewes0002a
drewes0002b…
The last step is to either use Adobe Acrobat or Automator to merge the individual files into a single PDF document. For the automator option you first need to create a PDF document only for the even pages and one for the odd. The “Shuffling pages” options allows you in a third step to combine these two PDF documents into one.
Since there were certain pages missing this solution was not sufficient. If for example page 3 was missing then the sequence would be:
1,2,5,4,7,6
It would also be great if the book’s page number would correspond to the PDF document page number. Meaning that if you got to page 103 in the PDF file, you would like to see page 103 from the book. The solution was to include white dummy pages for the missing pages.
The following pages then all need to be re-serialized. Meaning that you first have to move all the good page into a dedicated directory, call it “good images”. Add the white dummy pages with the the right serial number manually. You then rename all the remaining files in the original directory. I decided not to use the a/b suffix solution described above, but to re-serialize the files with an increment of 2. That way I could continue to look at each page scan and ensure that the page number in the scan was the same as its file name number. Jürgen Brandstetter was so kind to help me writing a small script to rename the files:
declare -i i=1; for file in *.jpg ; do new=$(printf "%04d.jpg" "$i"); mv "$file" "rename/drewes"$new; i=$[$i+2]; done
In this script i defines the starting number of the renaming. The script searches for all the files that end in .jpg and renames them starting with i. In case of the missing page 3 it would have to be for all of the following pages i=5. It is also important to notice that a directory called “rename” needs to present in the image folder. The renaming is done by moving the files into this directory.
I created a simple text document and saved it as script rename_serial_odd.sh on the desktop. Use the Terminal to make that file executable with:
chmod +x rename_serial_odd.sh
You should then use the Terminal to get to the directory in which the files are that you intend to rename and that also include the rename folder. You can then call the script as:
/Users/yourUserName/Desktop/rename_serial_odd.sh
You need to complete this process for both the even and the odd pages. The advantage of this method is that you can always check the filename against the page number of the book. Once you complete the adding of dummy pages and renaming the files, I moved the even and odd pages into one directory. The last step was to use Acrobat to merge all the files into a single PDF.